Script example for preprocessing raw data file
Download the Example Data Set and run the script below
Pitch Discrimination Task
Information about example data set:
Raw Data Filename: “pitch_discrimination_19-1_001 Samples.txt”
Eyetracker: SMI Red250 Mobile recorded at 250 Hz
Contains message markers: Yes
Subject #: 19
Task: Pitch Discrimination
Trial Procedure: Fixation (Pre-trial - 3000 to 2000 ms) -> Tone 1 (200 ms) -> Inter-stimulus Interval (ISI - 500 ms) -> Tone 2 (200 ms) -> Response Screen (Until response)
The ideal scenario is that you were able to insert message markers, that were synced to specific events in the experiment software, into the eyetracking data file itself. In this data set, that was the case. There are message markers in the data file when the trial events (stimuli) occured. A depiction of a trial procedure with message markers is given in the picture below.
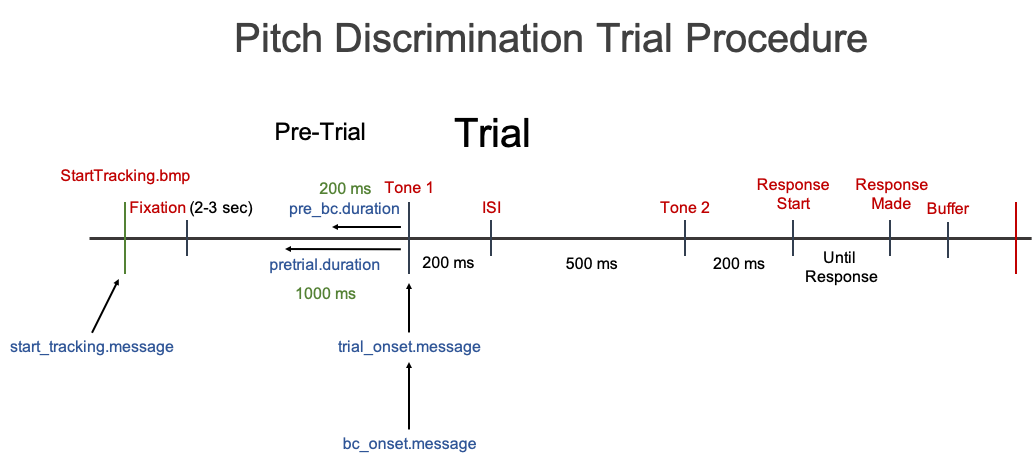
Each piece of the image is explained below
StartTracking Message
The first message marker is the StartTracking message. It is usually more practical to start saving data right at the beginning of a trial and stop saving at the end of a trial. This results in a smaller data file (less irrelevant data) than if you were to continously save data between trials or blocks. Different eye-tracker systems have a different default StartTracking message. For SMI eye-trackers it is StartTracking.bmp. Or you can just set the argument as default, start_tracking.message <- "default".
In the case where you continuously saved data and do not have a StartTracking message at the start of each trial, you can use the first stimulus event (usually the pre-trial event) as the StartTracking message. For instance, in this case it would be, start_tracking.message <- "Fixation" because there is a message labeled Fixation in the data stream at the start of every trial. But we do have a StartTracking message so we will use the default.
Trial Onset Message
It is good practice in eye-tracking and pupillometry to have a pre-trial period before the trial actually begins. This does several things. One is that it allows the pupil response to return to normal after the previous trial (less interference from one trial to the next). Another is that research has shown the pre-trial pupil size is predictive of performance on the trial and therefore can be useful information.
In this pitch discrimination task, the actual duration of the pre-trial period (in which there was a central fixation on the screen) was either 3000 or 2000 ms. To define what length we want the pre-trial duration to be cutoff at in the data file we need to specify the TrialOnset message. The TrialOnset message corresponds the message marker in the data file for the first stimulus of the actual trial. In this case it is Tone 1. Therefore, we can set trial_onset.message <- "Tone 1". Then we can set the pretrial duration relative to this message marker. Let’s go ahead and just set it as pre_trial.duration <- 2000.
In the final preprocessed data file, the Time column will be set relative to the TrialOnset message. Therefore, the start of Tone 1 will have a Time of or near 0, the pre-trial phase will have a Time value of -2000 to 0, and anything after Tone 1 will have a positive value.
There will also be a column labeled Stimulus that has a value in every row corresponding to what stimulus event that eye sample belongs to (e.g. Tone 1, ISI, Tone 2, Response Start, etc.).
Apply Baseline Correction
If testing for the difference in pupil dilation between conditions or participants, it is important to apply some type of baseline correction.
First, you need to specify where you want baseline correction to start being applied to by specifiying a message marker in the data, the BC Onset message. In this case (and many cases), the BC Onset message is the same as the TrialOnset message. Therefore we can set bc_onset.message <- "Tone 1". You can even apply baseline correction multiple times in one trial. For instance, we could apply baseline correction at Tone 2 as well if we set it as bc_onset.message <- c("Tone 1", "Tone 2").
When applying baseline correction you need to calculate the median pupil size for a certain duration before the start of the BC Onset message. For this example let’s set the duration to 200 ms, pre_bc.duration <- 200.
You need to decide which type of baseline correction to apply, subtractive or divisive.
In the final preprocessed data file there will be a new column for baseline corrected pupil data.
Other Parameters
Once you have the message markers all figured out you need to specify which preprocessing options you want to use.
For more details on the different options see the Article Preprocessing Options
# devtools::install_github("dr-JT/pupillometry")
library(pupillometry)
## Preprocessing parameters
# File Import Information
import.dir <- "data/Raw"
pattern <- "Samples.txt"
taskname <- "Pitch_Discrimination"
timing.file <- NULL
# Eyetrackers save the subject number information in different ways and is not
# always easy to obtain. For SMI Red250m eyetrackers this is extracted from the
# datafile name. For SR-Research Eyelink1000 eyetrackers this is extracted from
# the column name with the subject ID. You need to identify a unique subj.prefix
# pattern and subj.suffix pattern that surrounds the subject # in the
# datafile name/subject ID column.
subj.prefix <- "n_"
subj.suffix <- "-"
# File Output Information
output.dir <- "data/Preprocessed"
output.steps <- FALSE
files.merge <- FALSE
# Eyetracker Information
eyetracker <- "smi"
hz <- 250
eye.use <- "left"
px_to_mm.conversion <- NULL
# Message Marker Information
start_tracking.message <- "default"
start_tracking.match <- "exact"
trial_onset.message <- "Tone 1"
trial_onset.match <- "exact"
pre_trial.duration <- 1000
bc_onset.message <- "Tone 1"
bc_onset.match <- "exact"
# Preprocessing Options
deblink.extend <- 100
smooth <- "hann"
smooth.window <- 500
interpolate <- "cubic-spline"
interpolate.maxgap <- 750
method.first <- "smooth"
bc <- "subtractive"
pre_bc.duration <- 200
missing.allowed <- .30
# Misc.
subset <- "default"
trial.exclude <- c()
############################
pupil_preprocess(import.dir = import.dir, pattern = pattern, taskname = taskname,
subj.prefix = subj.prefix, subj.suffix = subj.suffix,
timing.file = timing.file, output.dir = output.dir,
output.steps = output.steps, files.merge = files.merge,
eyetracker = eyetracker, hz = hz, eye.use = eye.use,
px_to_mm.conversion = px_to_mm.conversion,
start_tracking.message = start_tracking.message,
start_tracking.match = start_tracking.match,
trial_onset.message = trial_onset.message,
trial_onset.match = trial_onset.match,
pre_trial.duration = pre_trial.duration,
bc_onset.message = bc_onset.message,
bc_onset.match = bc_onset.match,
deblink.extend = deblink.extend,
smooth = smooth, smooth.window = smooth.window,
interpolate = interpolate,
interpolate.maxgap = interpolate.maxgap,
method.first = method.first, bc = bc,
pre_bc.duration = pre_bc.duration,
missing.allowed = missing.allowed, subset = subset,
trial.exclude = trial.exclude)